
While working on a recent project, we faced a common challenge: analysing very long documents with Large Language Models (LLMs). Although modern LLMs can process impressive amounts of text (up to ~150K words), their ability to reason effectively deteriorates significantly when dealing with large quantities of information.
We observed that models tend to get confused when using more than half of the context window (typically above ~75K words), often forgetting or mixing up instructions. Additionally, processing these large documents led to significant practical challenges: we frequently hit rate limits in terms of tokens per minute, and the costs increased rapidly as each analysis required processing the entire document multiple times, even when using prompt caching techniques.
This combination of technical limitations and practical constraints led us to develop a new approach: Agentic R2A (Agentic Retrieval-augmented Analysis). The Agentic nature of this approach refers to its ability to execute multi-step workflows where each step is an agent with a specific task and feeds data into subsequent steps, creating a chain of interconnected analyses.
Beyond traditional RAG
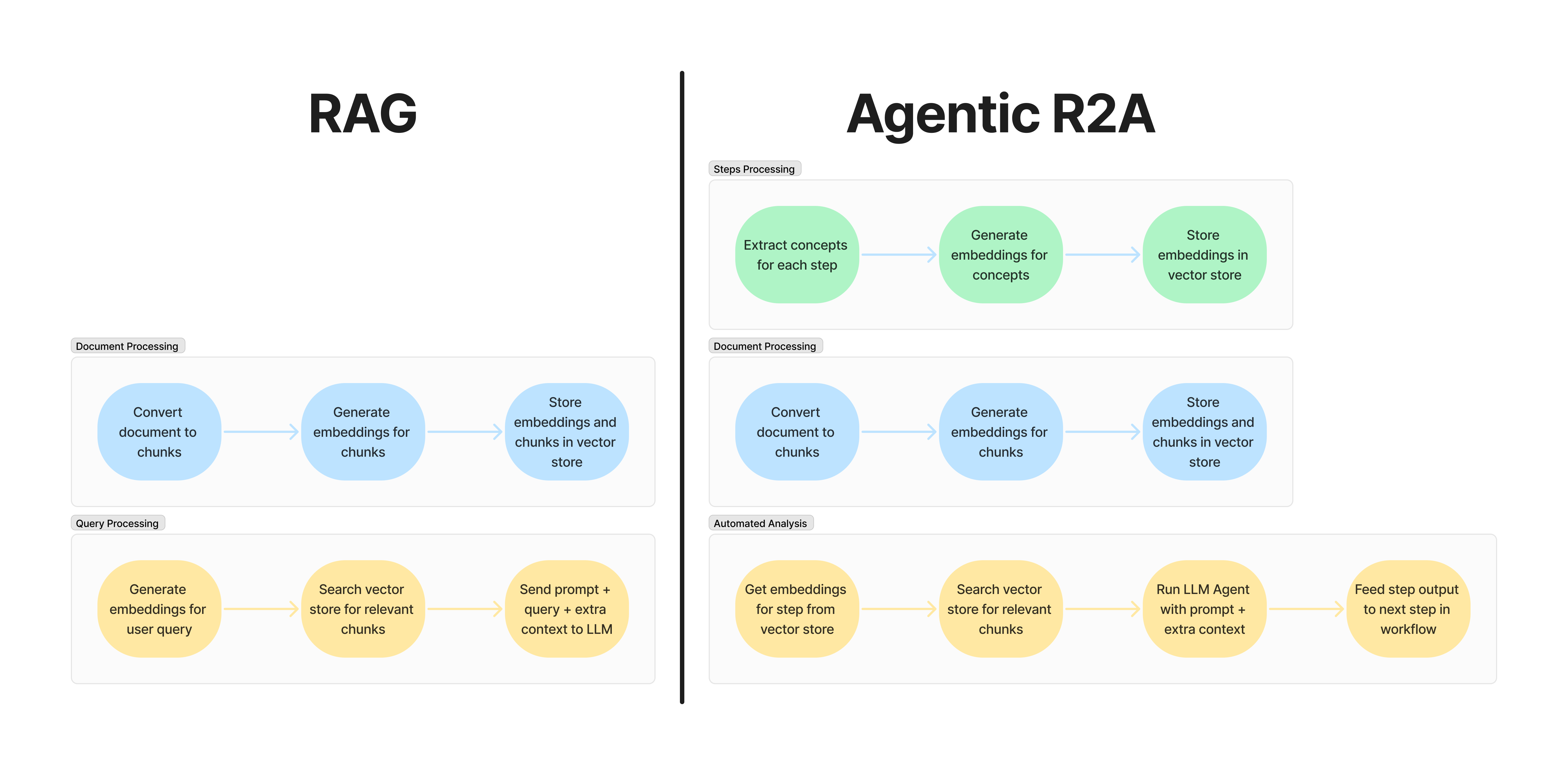
To understand Agentic R2A, first look at traditional Retrieval Augmented Generation (RAG). RAG operates in two stages:
- Document Processing: Converting documents into chunks and embeddings, storing them in a vector store
- Query Processing: Generating embeddings for user questions, finding relevant chunks, and using them to inform the LLM’s response
However, our use case was different. We needed to perform automated analysis of documents without user queries, following predetermined analysis steps. This realisation led us to develop Agentic R2A, which builds upon RAG’s foundations while optimising for automated workflows.
How Agentic R2A works
Agentic R2A introduces a three-stage approach:
-
Analysis Step Processing:
- Extract main concepts from each analysis step prompt to be used in similarity search for document chunks
- Generate embeddings for these concepts
- Store them in a vector store
-
Document Processing:
- Split documents into appropriately sized chunks
- Convert chunks into embeddings using models like Voyage, Cohere or OpenAI
- Store chunks in a vector store with metadata
-
Automated Analysis:
- For each analysis step, retrieve the pre-computed concept embeddings for that step and perform a similarity search against the document chunks in the vector store
- Run the Agent with a custom prompt specific to each analysis step and with the relevant chunks content
- Generate analysis output for each step and feed it to the next step in the workflow
Key differences from RAG
While RAG is optimised for chat contexts, Agentic R2A is explicitly designed for workflows. This fundamental difference leads to several advantages:
- No Runtime Embedding Generation: Unlike RAG, which needs to generate embeddings for each user query, Agentic R2A’s concept embeddings are generated once and reused for every workflow run.
- Workflow-Optimised Processing: Where RAG requires new prompt engineering for each user query, Agentic R2A operates on predefined workflows with carefully optimised prompts and analysis patterns consistent across runs.
- Sequential Analysis Steps: Unlike RAG’s independent query-response pattern, Agentic R2A works with Agents connected through analysis steps, where each step has a dedicated prompt and feeds data into subsequent steps. This creates a sophisticated chain of analysis that builds upon previous insights.
- Efficient Resource Allocation: RAG splits computational resources between embedding generation and LLM processing at runtime. Agentic R2A focuses resources on similarity search and LLM processing, making it more efficient for batch processing operations.
- Predictable Scaling: Unlike RAG, which scales with the number of user queries, Agentic R2A’s scaling is determined by document size and number of analysis steps, making it more predictable for production environments.
These fundamental differences make Agentic R2A particularly well-suited for automated document processing pipelines where consistency and efficiency are crucial.

Applications
Agentic R2A has proven particularly effective in several use cases:
Automating Online Course Creation:
- Process textbooks or educational materials as source documents
- Analysis steps focus on identifying key concepts, learning objectives, and examples
- Generate structured lesson plans by retrieving relevant chunks for each course module
Generating Podcast or Video Scripts:
- Analyse long-form content like research papers or articles
- Extract main talking points and supporting evidence through targeted retrieval
- Structure content into natural conversation flows using specific concept embeddings
Long Document Analysis:
- Process lengthy technical documentation or research papers
- Extract specific patterns, methodologies, or findings through targeted concept searches
- Create structured reports with consistent formatting and organisation
In each case, Agentic R2A’s workflow-centric approach ensures consistent output quality while efficiently handling large volumes of source material. The pre-computed concept embeddings for each analysis step ensure that the system quickly identifies and processes the most relevant portions of the source documents.
Implementation considerations
For optimal results, consider:
- Chunk sizing: Define minimum and maximum sizes for document chunks, balancing between context preservation and processing efficiency. If the document is divided into sections, aim to keep sections in the same chunk.
- Embedding quality: Choose appropriate embedding models for your domain, considering factors like semantic understanding, language support and cost. Different embedding models (Voyage, Cohere, OpenAI) have varying strengths in handling technical content, multiple languages or domain-specific terminology.
- Similarity thresholds: Adjust based on the specificity needed in the analysis. These thresholds often need adjusting based on document types and analysis requirements.
- Dynamic chunk retrieval: Scale the number of chunks based on document size and complexity, ensuring comprehensive coverage without overwhelming the LLM’s context window.
- Prompt engineering: Each Agent should only perform a single well-defined task and return a clear output. We can perform complex analyses with consistent results by combining multiple agents with different prompts.
- Document size: This technique only works well when the documents are larger than at least one-third of the context window (and it becomes really useful for documents above half the context window). Adding the full doc content in the prompt is still the best approach for smaller documents as it provides all the required information for all steps.
Conclusion
Agentic R2A represents a significant step forward in automated document analysis. By optimising the RAG approach for autonomous workflows, we’ve created a more efficient and effective system for processing large documents with LLMs.
The key innovation lies in its workflow-centric design, eliminating the need for runtime embedding generation while maintaining the benefits of retrieval-augmented approaches. As we continue to develop and refine this method, we expect to see even more applications where Agentic R2A can provide value in automated document analysis workflows.

The Non-Technical Founders survival guide
How to spot, avoid & recover from 7 start-up scuppering traps.
The Non-Technical Founders survival guide: How to spot, avoid & recover from 7 start-up scuppering traps.
